
自然语言处理共3篇
排序

AI接口服务平台,支持GPT-4o、Claude4、Grok-3等300+AI模型,可直接下单,超值优惠,国内访问稳定
Claude4中转API点击购买 专业的AI接口服务平台,支持GPT-4o、Claude-3.7、Grok-3、DeepSeek-V3等300+AI模型。价格仅为官方9.56%起,提供图像生成、联网搜索、文件分析等全功能服务。注册即送0.4...

MiniMax M1:百万Token上下文、混合注意力,新一代大语言模型横空出世!
各位小伙伴,今天给大家介绍一款超强的大语言模型——MiniMax M1!它可是全球首个开放权重的大规模混合注意力推理模型哦!是不是听起来就很厉害?别急,更厉害的还在后面呢! **M1的强大之处:...
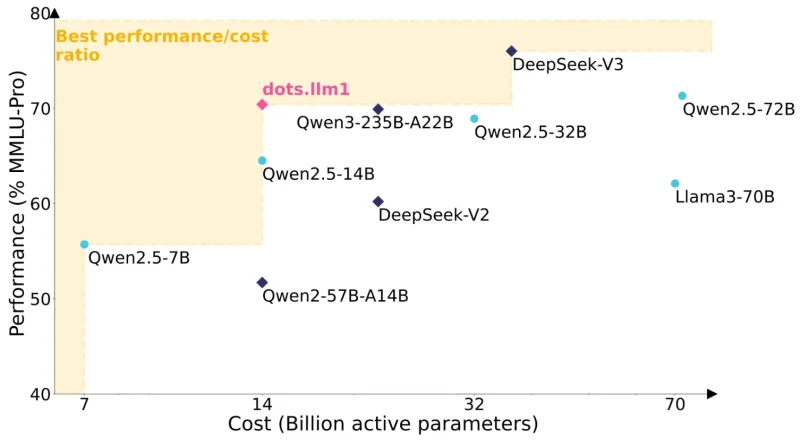
Dots.LLM1:开源MoE大模型,性能媲美Qwen2.5-72B,人人都能玩转!
还在为大模型的部署和使用成本发愁吗?想体验顶尖模型的性能,又不想被高昂的费用劝退?现在,机会来了!今天要给大家介绍一款超给力的开源大模型——**Dots.LLM1**,它不仅性能出色,而且还非...