
像专家一样使用 Codex,不是靠“神奇提示词”,而是建立一套
可复用、可验证、可控权限、可沉淀经验
让 Codex 做执行、探索、验证、整理;你负责目标、边界、验收和最终判断。
💡 核心摘要
- 专家级Codex使用强调结构化任务定义(目标、范围、约束、验收标准),而非模糊指令。
- 通过“只读分析”、AGENTS.md、/plan、/goal 等命令,建立Codex对项目的全面认知和分阶段执行能力。
- 精细化权限管理、强制自动化测试、多维度审查(/review, Subagents)是确保代码质量和风险控制的关键。
- 利用Skills、自定义Slash Command和MCP连接外部上下文,实现工作流自动化与效率提升。
- 持续复盘与经验沉淀,将最佳实践融入AGENTS.md,形成正向循环,最终由人类进行最终判断和验收。
一、引言
在软件开发领域,AI辅助编程工具如Codex正日益普及,极大地提升了开发效率。然而,许多开发者在使用初期,往往停留在“给我写一段代码”的模糊指令阶段,导致AI产出质量不稳定,甚至引入新的问题。这种粗放式的使用方式,不仅未能充分发挥Codex的潜力,反而可能增加调试和返工成本。
本文旨在揭示Codex专家级使用的方法论,帮助开发者从“提示词工程师”转变为“AI工作流架构师”。我们将深入探讨如何构建一套可复用、可验证、权限可控且能沉淀经验的Codex工作流,确保AI在执行、探索、验证和整理任务时,始终在人类设定的目标、边界和验收标准之内。通过掌握这些策略,您将能够像资深工程师一样,驾驭Codex,显著提升开发效率和代码质量,并最终做出关键的工程判断。
二、建立高效协作基础:明确目标与环境认知
【核心结论】专家级Codex使用始于清晰的任务定义和对项目环境的全面理解。模糊指令是低效的根源,而结构化的任务描述和对项目上下文的充分认知,是Codex高效、准确执行任务的前提。
【解释依据】Codex并非拥有人类的常识和上下文理解能力。当您说“帮我做一个登录功能”时,它可能无法理解您的项目技术栈、现有架构、安全要求和验收标准。这会导致其生成不符合预期的代码,甚至破坏现有功能。相反,通过明确的目标、范围、约束和验收标准,Codex能更精准地理解任务意图。同时,让Codex先“只读分析”项目,并维护AGENTS.md,是建立其工作上下文的关键,避免其在不了解项目全貌的情况下盲目修改。
【场景化建议】
- 结构化任务定义: 每次任务前,务必为Codex提供详细的指令,包括:
- 目标: 任务要达成的具体成果。
- 范围: 允许Codex修改或影响的文件/模块。
- 约束: 不允许Codex做的事情(如不新增依赖、不修改现有UI风格)。
- 验收标准: 衡量任务完成度的具体、可验证条件。
- 执行流程: 明确Codex应如何分步执行(如先分析再规划)。
例如,不要说“帮我做一个登录功能”,而应说:
目标:为现有项目增加邮箱+密码登录功能。
范围:前端:登录页、表单校验、错误提示;后端:登录 API;数据库:如有必要新增用户表字段。
约束:不新增大型依赖;保持现有 UI 风格;不要直接提交 commit。
验收标准:1. 空邮箱、错误邮箱、错误密码都有提示;2. 登录成功后跳转到 dashboard;3. 登录失败不泄露用户是否存在;4. 添加必要测试;5. npm test / lint / typecheck 通过。
工作方式:先阅读代码并给实现计划,不要马上修改。 - 项目初探与只读分析: 当Codex接触新项目或新模块时,首先让它进行“只读分析”,而不是立即修改代码。
请只阅读项目,不要修改任何文件。
输出:1. 项目是做什么的;2. 技术栈;3. 目录结构;4. 关键业务流程;5. 启动、测试、构建命令;6. 最容易出问题的模块;7. 建议写入 AGENTS.md 的项目规则这有助于Codex建立对项目上下文的理解,并防止其在不了解全貌的情况下进行破坏性操作。
- 维护 AGENTS.md: AGENTS.md是Codex专家级使用的核心。它允许您定义全局指导和项目级规则,确保Codex每次任务都有一致的期望和行为模式。官方最佳实践建议使用`/init`快速生成初始AGENTS.md,但您应手动编辑,使其符合团队真实的构建、测试、review和发布流程。
每次Codex犯错,都应将相应的规则补进AGENTS.md。例如,如果它经常乱加依赖,您可以添加:
禁止新增依赖,除非先说明原因、替代方案和体积影响,并获得确认。
三、精准执行与风险控制:规划、长任务与权限管理
【核心结论】面对复杂或长周期任务,专家会通过分阶段规划、持续目标设定和精细化权限管理来控制风险并确保执行质量。每次执行后的自动化测试是验证成果的必要步骤。
【解释依据】直接让Codex执行大型复杂任务极易失控。`/plan`命令强制Codex先进行任务分解和风险评估,而`/goal`则适用于需要持续迭代、有明确停止条件的长周期任务。Codex的sandbox机制和权限模式(只读、常规开发、高风险操作)是防止意外修改的关键。此外,不盲信Codex的“完成”声明,而是通过强制运行自动化测试来验证其成果,是确保代码质量的底线。
【场景化建议】
- 用 /plan 控制复杂任务: 专家不会让Codex直接做大任务,而是先规划。
/plan
我要把当前项目的支付流程重构成更清晰的 service 层。
请先分析影响范围、风险、迁移步骤和测试策略。
不要修改代码。官方建议先用`/plan`塑形,再用`/goal`。您可以要求Codex按特定格式给出计划,例如:
请按这个格式给计划:1. 你理解的目标;2. 涉及文件;3. 风险点;4. 分阶段方案;5. 每阶段验收标准;6. 需要我确认的问题计划未通过前,绝不允许Codex修改代码。
- 用 /goal 处理长任务: 当任务不是一次就能完成,如迁移、重构、修复大量测试时,使用`/goal`。它适合让Codex围绕一个可验证的停止条件持续工作。
/goal Complete the migration from local state to Zustand.Stop only when:
1. App behavior is unchanged
2. All tests pass
3. npm run build succeeds
4. State management code is documented
5. A migration summary is written停止条件必须具体且可验证,例如“修复所有 failing tests”、“完成技术栈迁移”等。
- 权限分模式,不一直全开放: Codex的sandbox机制是其自主行动但受限的关键。专家会根据任务风险切换权限模式。
- 只读分析模式: 适合读代码、审查、解释、规划。
/permissions 切换到 read-only。请分析当前项目的认证流程,不要修改代码。 - 常规开发模式: 适合日常写代码、跑测试。
codex –sandbox workspace-write –ask-for-approval on-request此模式下,Codex可在工作区读写和运行命令,但越界操作需批准。
- 高风险操作模式: 凡是涉及删除文件、数据库迁移、生产配置、密钥、支付、认证权限、CI/CD、部署、批量重构等,都应明确限制Codex的修改权限。
这是高风险任务。只允许分析和提出方案,不允许修改文件、运行迁移、删除数据或改配置。
- 只读分析模式: 适合读代码、审查、解释、规划。
- 每次都让它跑测试: 专家不会相信Codex口头上的“完成了”,而是相信测试结果。
请完成修改后运行:1. npm run lint;2. npm run typecheck;3. npm test;4. npm run build。
如果失败:- 先解释失败原因;- 再修复;- 不要掩盖测试;- 不要删除测试。如果无法运行测试,应要求Codex明确说明原因,并告知手动运行哪些命令。
四、优化与自动化:审查、上下文与经验沉淀
【核心结论】专家通过多维度审查、流程自动化和外部上下文集成,不断优化Codex的工作效率和输出质量,并将经验沉淀为可复用资产,形成正向循环。
【解释依据】单一视角的审查不足以发现所有问题,`/review`和Subagents提供了多角度的质量保障。Skills和自定义Slash Command将重复性工作流标准化,提升效率。MCP则将Codex与GitHub、Jira、Figma等外部系统连接,提供更全面的决策上下文。定期压缩上下文避免遗忘,并沉淀经验到AGENTS.md或Skills,形成正向循环。
【场景化建议】
- 用 /review 当第二双眼睛: 写完代码后,不要立刻合并。让Codex进入review模式。
/review
请 review 当前未提交改动,重点检查:1. 逻辑 bug;2. 安全风险;3. 边界条件;4. 测试缺失;5. 过度设计;6. 是否违反 AGENTS.md官方命令说明中,`/review`可用于审查未提交改动或和base branch比较。您可以要求Codex按严重程度(P0/P1/P2)输出问题描述、相关文件、风险原因和建议修复方式。
- 用 Subagents 做并行专家审查: Subagents是高级功能,允许Codex生成专门的子agent并行探索、处理或分析任务,最后汇总结果。
请使用 subagents 并行审查当前改动:
Agent A:检查业务逻辑和边界条件
Agent B:检查安全、认证、权限问题
Agent C:检查测试覆盖
Agent D:检查性能和可维护性
Agent E:检查 UI/UX、移动端、可访问性不要修改代码。
最后合并成一份 review 报告,按严重程度排序。这适用于上线前审查、大型重构、安全敏感功能等场景。
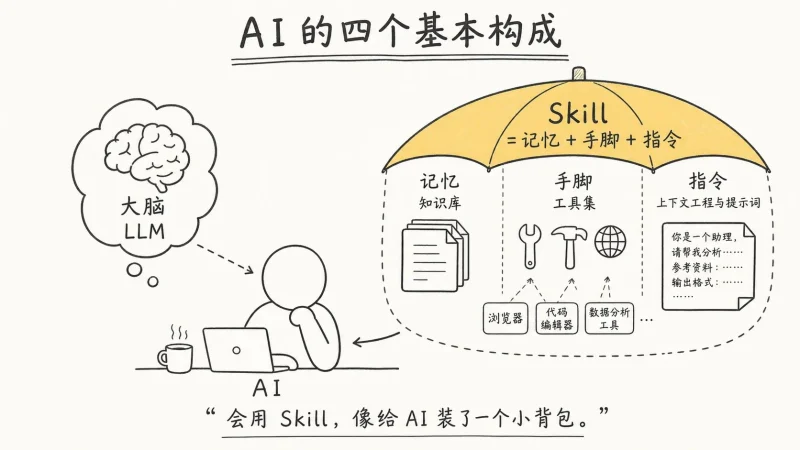
- 用 Skill 封装重复流程: Skills是Codex高阶能力之一,是由说明、资源和可选脚本组成的任务能力包,让Codex更可靠地执行特定工作流。将常用流程封装成Skill,而不是每次都写长提示词。例如,创建一个名为`frontend-polish`的Skill,其SKILL.md可以写:
请优化当前 dashboard 页面,但不要改业务逻辑。
Skills可在Codex CLI和IDE扩展中使用,可显式调用或让Codex自动选择。
- 用自定义 Slash Command 做快捷工作流: Codex CLI的slash commands可以快速切换模型、调整权限、总结长对话,也能创建自定义命令。例如,定义一个`/deep-review`命令:
请深度 review 当前 diff。检查:1. correctness;2. edge cases;3. security;4. performance;5. tests;6. maintainability;7. whether it follows AGENTS.md
不要修改代码。
按 P0/P1/P2 输出。这样,每次输入`/deep-review`就能复用整套审查流程。
- 用 MCP 连接外部上下文: MCP(Multi-Context Provider)的价值在于让Codex不只看本地代码,还能接入外部系统,提供更全面的上下文。例如,您可以让Codex连接GitHub(读issue、PR、CI结果)、Linear/Jira(读任务和验收标准)、Figma(读设计稿)、Sentry(读线上错误)、Notion(读产品文档)等。
请读取这个 Linear ticket 的验收标准,再检查当前代码是否满足。
如果不满足,先给实现计划,不要修改代码。请根据 Sentry 错误日志定位问题。
要求:1. 找到可能的代码位置;2. 给复现路径;3. 判断影响范围;4. 提出最小修复方案;5. 不要直接改代码。 - 长会话要定期压缩上下文: 长任务最容易跑偏。当任务做了很久,使用`/status`查看上下文使用量,并主动“整理战场”。
请总结当前任务状态:1. 原始目标;2. 已做改动;3. 已确认的决策;4. 失败过的尝试;5. 当前剩余问题;6. 下一步计划;7. 需要继续遵守的约束。
后续请基于这个摘要继续。这能避免Codex忘记前面的约束,保持任务焦点。
五、核心对比与注意事项
以下表格对比了新手与专家使用Codex的关键差异,并列出了使用Codex的注意事项:
| 维度 | 新手使用Codex | 专家使用Codex | 注意事项 |
|---|---|---|---|
| 任务指令 | 模糊、宽泛的“帮我写代码” | 结构化、明确的目标、范围、约束、验收标准 | 指令越清晰,Codex产出越精准;避免歧义。 |
| 项目认知 | 直接开始修改,缺乏全局观 | 先“只读分析”项目,理解技术栈、架构、业务流程 | 在Codex修改代码前,确保其已充分理解项目上下文。 |
| 规则管理 | 无特定规则,每次都重新指示 | 维护 AGENTS.md,沉淀团队规范和经验 | AGENTS.md是团队知识库,需持续更新和完善。 |
| 复杂任务 | 直接让Codex完成,易失控 | 先用 /plan 规划,再用 /goal 持续执行 | 将大任务拆解为小步骤,分阶段验证。 |
| 权限控制 | 默认全开放,风险高 | 根据任务风险切换只读、常规、高风险模式 | 高风险操作(如删除文件、数据库迁移)需严格限制。 |
| 结果验证 | 依赖Codex自述“完成”,不强制测试 | 强制运行 lint、typecheck、test、build 等自动化测试 | 永远不盲信,以实际测试结果为准。 |
| 代码审查 | 人工审查或无审查 | 用 /review 和 Subagents 进行多维度、并行审查 | AI审查是辅助,最终决策仍需人工确认。 |
| 效率提升 | 重复输入长提示词 | 封装 Skill 和自定义 Slash Command 自动化流程 | 标准化重复性工作,减少人工干预。 |
| 上下文管理 | 仅限于当前对话,易遗忘 | 用 MCP 连接外部系统,定期压缩上下文 | 提供丰富上下文,避免Codex“失忆”。 |
| 经验沉淀 | 无沉淀机制 | 任务后复盘,将经验沉淀到 AGENTS.md / Skill | 构建可复用知识库,持续优化AI工作流。 |
六、常见问题 (FAQ)
1. 为什么不能直接让Codex“帮我写代码”?
直接的“帮我写代码”指令过于模糊,Codex缺乏对项目上下文、具体需求、技术栈、编码规范和验收标准的理解。这会导致它生成不符合预期、存在潜在bug或与现有代码不兼容的代码。专家级使用强调提供结构化的目标、范围、约束和验收标准,引导Codex在明确的框架内高效工作。
2. AGENTS.md在Codex工作流中扮演什么角色?
AGENTS.md是Codex的“行为准则”和“项目手册”。它允许您定义全局和项目级的规则、编码规范、测试要求、安全策略等。Codex在开始任务前会读取AGENTS.md,确保其行为符合团队的期望和标准。通过持续更新AGENTS.md,可以将团队的经验和最佳实践沉淀下来,使Codex的学习和执行更加稳定和可靠。
3. 如何确保Codex不会随意修改我的项目代码?
确保Codex不会随意修改代码主要通过以下几个方面:首先,在任务指令中明确“不要修改代码”或“只允许分析”等约束。其次,利用Codex的权限管理机制,根据任务风险切换到“只读分析模式”。对于需要修改代码的任务,使用“常规开发模式”并开启`–ask-for-approval on-request`,让Codex在进行越界操作时请求批准。最后,始终要求Codex在修改后运行自动化测试(lint, typecheck, test, build),并进行人工`/review`,确保所有改动都经过验证和审查。
七、结论
Codex作为强大的AI编程助手,其潜力远不止于简单的代码生成。像专家一样使用Codex,意味着从被动接受AI产出,转变为主动构建一套严谨、可控、可优化的AI辅助开发工作流。这要求我们从任务定义、环境认知、执行规划、风险控制、质量保障到效率提升和经验沉淀,都采取结构化、系统化的方法。
通过采纳本文介绍的策略,如明确任务目标、维护AGENTS.md、善用/plan和/goal命令、精细化权限管理、强制自动化测试、多维度审查(/review, Subagents)、流程自动化(Skills, Slash Command)以及集成外部上下文(MCP),您将能够显著提升Codex的效能,降低开发风险,并最终将Codex融入到您的专业工程实践中。请记住,Codex负责高强度执行,而您,作为专家,则负责最终的工程判断和验收。永远不盲信Codex,而是将其视为一套严密工作流中的高效工具。





暂无评论内容