
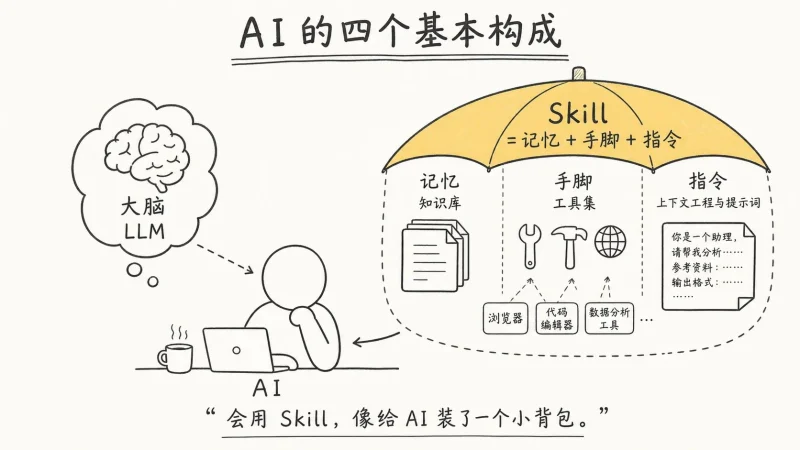
💡 核心摘要 (TL;DR)
1. LlamaIndex 将文档解析器 LiteParse 完全用 Rust 重写,实现 457 页 PDF 在 0.777 秒解析完成。
2. 支持 Python、Node、Rust 与浏览器多平台运行,提供结构化 JSON、纯文本和页面截图三种输出模式。
3. 内置 OCR、Agent Skill 集成,开源免费,适合 RAG 管道和本地 AI 文档处理。
Rust 重写的优势
LiteParse v1 使用 Node.js,受限于进程启动和运行时性能。v2 用 Rust 完全重写后,小文档解析速度提升 5 到 100 倍,大文档提升 3 倍。
Rust 版本还带来多平台原生支持:同一核心代码通过 PyO3、napi-rs、Rust crate 和 WASM 包,可直接在 Python、Node、Rust 和浏览器运行。
![图片[1]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/a748b805fe20260528215426.webp)
支持文档格式与输出选项
输入端支持 PDF、DOCX、XLSX、PPTX 及图片。PDF 使用 PDFium 提取文本,其他格式通过 LibreOffice 与 ImageMagick 转换后处理。
输出方式包括结构化 JSON(保留文本定位和 bounding box)、纯文本(保留版面布局)以及页面截图 PNG,用于 LLM Agent 的视觉理解。
![图片[2]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/7380e375ea20260528215429.webp)
OCR 实现方式
内置 Tesseract,零配置即可使用。如识别精度不够,可接入 HTTP OCR 服务(EasyOCR、PaddleOCR 或自建),接口规范统一。
解析流程:先用 PDFium 提取原生文本,再对扫描页或图片页做选择性 OCR,最后合并结果并通过网格投影还原空间布局,实现速度与精度平衡。
![图片[3]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/756d6b07bd20260528215433.webp)
跨平台安装指南
| 平台 | 安装命令 |
|---|---|
| Python | pip install liteparse |
| Node/TypeScript | npm i @llamaindex/liteparse |
| Rust | cargo add liteparse(库)或 cargo install liteparse(CLI) |
| 浏览器 | @llamaindex/liteparse-wasm,可直接本地运行文档解析 |
四个平台均自带统一 CLI 工具 lit,解析文档命令:lit parse document.pdf
![图片[4]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/d9a796bc6220260528215437.webp)
性能基准
457 页、100MB PDF 解析耗时仅 0.777 秒,小文档比 v1 快 5 到 100 倍。性能提升源于消除 Node.js 进程开销及 Rust 的原生内存管理和并发能力。
适合 RAG 管道或批量文档处理,本地即可完成解析,无需依赖云端服务。
![图片[5]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/e2cddfee8620260528215440.webp)
Agent Skill 集成
LiteParse 提供现成 Agent Skill 文件,一行命令即可加入 AI Agent 工具链:npx skills add run-llama/llamaparse-agent-skills --skill liteparse
实现本地 PDF 解析输出结构化文本,无需网络请求或 API key。项目开源,遵循 Apache 2.0 协议,GitHub 上 5.5k Star。
![图片[6]-LlamaIndex LiteParse Rust 重写:457 页 PDF 秒级解析终极指南-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2026/05/4e80c8e8be20260528215444.webp)
核心概念对比表
| 特性 | v1 (Node.js) | v2 (Rust) |
|---|---|---|
| 解析速度 | 受 Node.js 启动和运行时影响 | 小文档快 5-100 倍,大文档快 3 倍 |
| 多平台支持 | 有限 | Python、Node、Rust、WASM |
| 输出类型 | 仅文本 | JSON、纯文本、PNG 截图 |
| OCR 集成 | 外部配置 | 内置 Tesseract,可接 HTTP OCR |
| Agent 集成 | 无 | 提供 Agent Skill 文件 |
| 开源许可 | 未知 | Apache 2.0 |
常见问题 (FAQ)
Q1: LiteParse v2 支持哪些文档格式?
A1: 支持 PDF、DOCX、XLSX、PPTX 和图片,PDF 使用 PDFium 提取文本,其余格式通过 LibreOffice 与 ImageMagick 转换处理。
Q2: 如何在本地多平台使用 LiteParse?
A2: Python 使用 pip install liteparse,Node/TypeScript 使用 npm i @llamaindex/liteparse,Rust 使用 cargo add/ install liteparse,浏览器使用 @llamaindex/liteparse-wasm,统一 CLI 命令 lit parse document.pdf。
Q3: OCR 与 Agent Skill 如何使用?
A3: 内置 Tesseract 支持零配置 OCR,可挂 HTTP OCR 服务器。Agent Skill 文件可直接集成到 AI Agent,实现本地文档解析输出结构化文本,无需网络请求或 API key。





暂无评论内容