
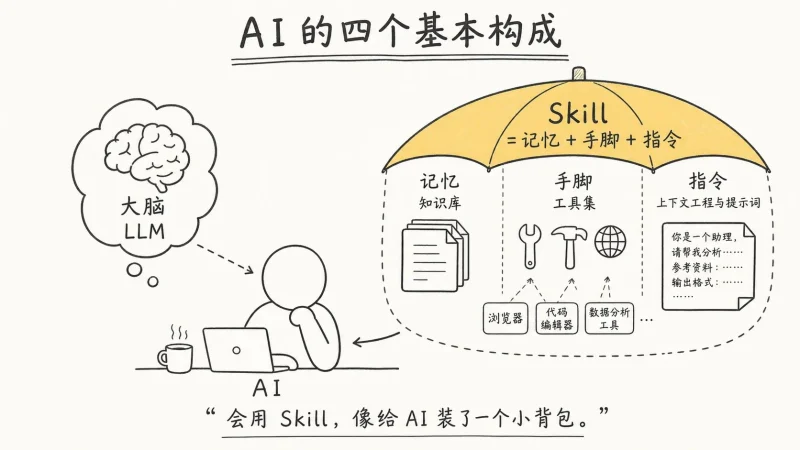
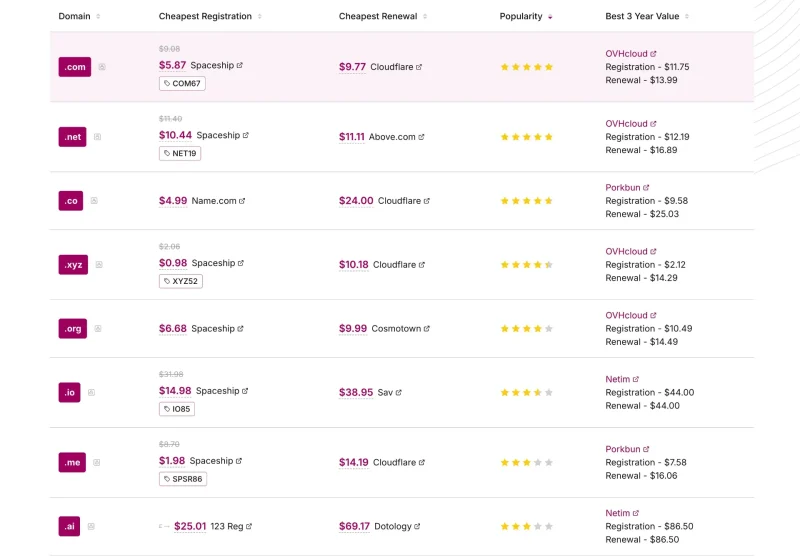
所谓的人生知识库 聊天记录是最重要的一个环节
每个人都在微信、Telegram、Discord 里日复一日地聊着。你的朋友、同事、导师——他们在对话中倾泻出的经验、观点、知识,远比他们发在公众号或博客上的内容更原始、更真实、更密集。但聊天记录躺在本地数据库里,像一座没有索引的图书馆,搜索靠回忆,提取靠截图。
怎么把聊天记录变成可用、可检索、可对话的知识库
2025 年我写过第一版,现在有几件事过时了,得更新。
在讲怎么做之前,先想清楚为什么做、能拿来干什么——用途不同,清洗策略、存储方式、检索逻辑完全不一样。
一、聊天记录能用来做什么
1.1 个人记忆外挂
人脑的遗忘速度远超想象。三个月前朋友推荐了一本书,你当时说”记下了”,现在只剩下模糊的影子。聊天记录是最高保真的个人记忆备份。
典型场景:”上次老刘推荐的那个宁波海鲜店叫什么来着?””李姐说过她小孩今年中考,是几月份来着?””去年团建定的是哪家民宿,有链接吗?”
这些答案就躺在聊天记录里,但你的人脑索引早就失效了。用关键词加语义检索双通道,一把就能捞出来。记忆类查询高度依赖时间维度,建议检索时默认按时间倒序排列,并在结果中展示时间戳——同样一句话,三年前说的和上周说的,意义完全不同。
1.2 数字分身(Digital Twin)
用一个人的聊天记录训练或微调模型,让它模仿这个人的说话方式、知识结构、甚至思维习惯。
可以做的事:模仿某个朋友的语气开玩笑;让技术大佬的”分身”替你答疑;团队中关键人物的离职知识承接——”如果老王还在,他会怎么评估这个方案?”
技术路径有三条,按成本递增。第一条是 RAG 加 Prompt 模板,不需要训练,System Prompt 描述其风格特征,检索相关发言作为 few-shot 示例,可控但模仿深度有限。第二条是 LoRA 微调,清洗后数据格式化为 instruction-response 对,风格抓得更像,但需要至少数千条高质量数据。第三条是微调模型学风格加 RAG 注入具体知识,效果最好,工程量和成本都高。
无论选哪条路,都需要从聊天记录里提取该人的发言模式画像——不是内容,是风格:平均消息长度、口头禅、标点偏好、表情密度。这些指标决定了模仿的可信度。
1.3 知识传承与团队记忆
团队里总有那么一两个人——什么都知道,什么都找他们。他们一旦离职,知识断崖式流失。聊天记录是捕获这类隐性知识的最后机会。
新人 onboarding 时,可以直接问”我们之前为什么选 gRPC 不选 REST?”,从历史讨论里拿到多角度的决策上下文,而不只是 wiki 上冰冷的结论。关键决策的复盘,能回溯原始讨论,看看当时考虑了什么、放弃了什么、忽略了什么,这比事后写的复盘报告真实一百倍。技术群里日复一日的”这个报错怎么搞””pod 起不来””OOM 了”——这些踩坑记录的价值不亚于任何技术文档。
1.4 内容创作的素材池
写文章、做视频、写方案的人总有这个时刻——”我记得上次聊过这个话题,观点很好,但具体怎么说的来着?”
聊天记录是内容创作者的素材矿脉:话题灵感(群里反复讨论的问题,就是你目标读者也在关心的问题)、素材引述(朋友的精辟观点,获得授权后可以直接引用)、结构参考(一场讨论的展开方式天然就是一篇好文章的骨架)。
更进阶的做法是让 LLM 自动从聊天记录里提取可成文的选题。每隔几条消息做一次采样,判断其中是否包含值得展开的话题,成本不高,效能很好。
1.5 社交关系洞察
不涉及窥探,而是帮助你更好地维护关系。关系热度追踪——你和某个朋友的聊天频率是上升还是下降?上一次主动联系是什么时候?重要日期提醒——聊天中提到”下个月我妈生日””我下周二面试”,自动提取并添加到日历。对话中的语气变化趋势,及时发现某段关系正在疏远。
1.6 个人成长档案
聊天记录是你认知演变的最高精度记录。回头看你三年前在一个话题上的发言,经常会产生”我真的说过这种话?”的惊讶感——这恰恰说明你成长了。
同一个话题,2022 年和 2025 年你分别说了什么?差异就是成长的刻度。当时做某个选择的理由,后来被证明是对还是错?原始对话比日记更诚实。你什么时候开始讨论某个新技术?从”听说过”到”在生产环境用了”间隔多久?这种演变轨迹在任何正式输出里几乎不可见。
1.7 训练专属 AI 助手
比数字分身更宽泛——用你和朋友的集体智慧,训练一个真正理解你语境的私人 AI。
和通用 AI 的区别在于:通用 AI 对”Redis”给的是标准定义,基于聊天记录的 AI 知道的是你们团队用它的方式和踩过的坑。通用 AI 给出通用推荐,这个 AI 的推荐基准是你朋友圈的审美和判断标准。通用 AI 回答”我该不该学 Rust”会给一堆利弊分析,而基于你聊天记录的 AI 会说”你们团队主力是 Go,王工去年试过 Rust 写微服务觉得生态不够成熟,建议先观望”——这才是你要的答案。
二、数据从哪来
思路没变,工具跟上了。
微信 PC 端数据库仍是 SQLCipher 加密的 SQLite,路径没变。变化在工具侧。
现在已支持微信 4.0,GitHub Star 接近 4 万,是目前覆盖面最广的导出方案,带 GUI,导出格式含 CSV、HTML、JSON。
2025 年 10 月仍有更新,API 更稳定,适合接进自动化 pipeline。
是 Java 版本,适合不想跑 Python 的场景,支持引用消息、表情、多实例。
安卓端如果需要,ppwwyyxx/wechat-dump 最后验证时间是 2025 年 1 月,仍可用,但需要 root。
导出目标仍然是结构化 JSONL,每条记录至少包含:
Telegram / Discord
没有变化。Telegram 官方导出 JSON 依然是最干净的路径,DiscordChatExporter 仍在维护,支持按频道、按时间范围导出为 JSON、HTML、CSV。
三、数据清洗——最脏的活
聊天数据和博客、论文最大的区别:噪声极高。聊天是即兴的、碎片化的、充满语境依赖的。不做清洗直接灌进 RAG 系统,检索结果会充满垃圾。
3.1 去噪
表情包、图片、语音的语义信息基本丢失,语音需要 ASR 转写,成本高收益低,一般直接过滤。系统消息(”张三邀请李四加入了群聊””撤回了一条消息””拍了拍”)是元信息,不含知识,用正则匹配模式剔除。
但短消息不是一律无用。”对,就是 Attention Is All You Need 那篇”——这种短消息是对上下文的确认或补充,需要保留。
的处理有个升级建议:不过滤,而是在 metadata 里打标。情绪化发言有时恰恰是观点最真实的那一刻,完全过滤会丢信号。打标之后,让 RAG 检索时选择权交给用户。
——手机号、身份证、住址、银行卡——绝对不能进知识库,用正则加 NER 双重过滤。
3.2 合并碎片发言
聊天是实时的,一个人可能连续发 5 条消息表达一个完整意思:
这四条必须合并成一段才构成有意义的知识片段:
time_gap 建议 60 秒,不再建议 30 秒下限——微信手机端打字慢,30 秒拆散正常连续发言的概率很高。
3.3 话题切分:语义分块替代时间切分
2025 年版推荐的时间切分(超过 30 分钟视为话题断裂)是一个合理的 fallback,但不是最优解。2025 年开始主流叫法是
(Semantic Chunking),核心思想:不按字数或时间切,按语义相似度的突变点切。
实现方式是把相邻消息段的 embedding 做余弦相似度计算,相似度急剧下降的位置就是话题切换点:
比让 LLM 做语义切分便宜一个数量级,效果比时间切分好不少,中文场景推荐先跑这个。
3.4 去重与过滤
同一话题反复聊——技术群里”Python 还是 Go”这种经久不衰的话题,每月聊一次,内容高度重复。用 embedding 余弦相似度做去重:
3.5 上下文修复:Contextual Retrieval
2025 年版提到”LLM 重写,把省略信息补全”,这个思路在 2024 年底被 Anthropic 系统化成了一个方法:
Contextual Retrieval
聊天高度依赖上下文,大量代词和省略:
李四: RAG的检索器你用什么?
张三: 用BM25
李四: 效果怎么样?
张三: 还行,召回率大概70%
“还行,召回率大概70%”——单独拿出来毫无意义。
做法是在存入向量数据库之前,给每个 chunk 加一段 LLM 生成的上下文摘要前缀,让 chunk 能”自我解释”:
存进向量库的是 context_prefix + chunk 的合体,检索时精度明显提升,尤其对代词密集、省略严重的聊天内容效果显著。成本是额外的 LLM 调用,用小模型(Gemini Flash 2.0 或 Qwen2.5-7B)控制成本完全可接受。
四、构建知识库
清洗完的数据,接下来怎么变成可用的知识库。
4.1 Embedding 模型选型(2026)
2025 年版推荐的 BAAI/bge-large-zh-v1.5 现在已经不是最优选了。
2026 年初格局大变,主要原因是
Matryoshka Representation Learning(MRL)
成为行业标准。MRL 的意思是:同一个 embedding 向量,截断前 N 维仍然有效,存储成本可以按需压缩,质量优雅降级而不是断崖式崩溃。
当前推荐:本地部署中文优先,仍推荐
BAAI/bge-m3
,568M 参数,同时支持稠密、稀疏、多向量三种检索方式,100 多个语言,中文开源 benchmark 依然稳。想追新的可以试
Qwen3-Embedding-8B
,阿里开源,中文性能超 bge-m3,但资源需求更高。API 方案综合最强的是
Gemini Embedding 2
,32K 上下文,5 种模态,100 多个语言,个人用有免费 tier 够了。性价比选
Jina v5-text-small
,677M 参数,Apache 2.0 开源,MTEB 表现优秀。对话里混有图片内容需要处理的场景,考虑
Voyage Multimodal 3.5
,MongoDB 2025 年以 2.2 亿美金收购了 Voyage AI,文字加图片加视频都支持。
4.2 关键词检索(BM25)
最轻量的方案。用 Elasticsearch 或 Meilisearch 建倒排索引,直接全文检索。零 GPU 成本,部署简单,对精确术语检索效果好(搜”SQLCipher”比 embedding 检索准)。缺点是不理解语义,搜”加密”搜不到”cipher”,无法处理口语化表述。
4.3 向量检索已经不够了
2025 年版的混合检索(BM25 加向量加 Reranker)在 2026 年依然是基线,但有个新问题:跨段落的关联推理。
比如你问:”老刘在 2024 年下半年对 K8s 的态度有没有变化?”这个查询需要跨时间跨对话段做关联推理,Top-K 向量检索拉出几个孤立片段,扔给 LLM 去综合,效果很差。这就是 GraphRAG 要解决的问题。
4.4 LightRAG:GraphRAG 的实用替代
GraphRAG(微软 2024 年提出)的核心思路是:先用 LLM 从文本里提取实体和关系,构建知识图谱,检索时走图而不走向量。对”谁认识谁””某个概念在哪些对话里出现过”这类问题,精度远超纯向量检索。
问题是 GraphRAG 贵。提取实体关系需要大量 LLM 调用,处理 1500 条以上的消息段,成本可能超出预期 3-5 倍。
2024 年 10 月出现了
,思路相同但 token 消耗减少约 90%,通过双层检索(局部实体检索加全局社区检索)实现接近 GraphRAG 的效果。
对于聊天知识库,LightRAG 的实际价值在于:”老王提到过哪些关于 Rust 的观点”——图检索,直接走实体加关系加实体。”我们群里对微服务架构的主流态度是什么”——社区摘要,聚合多个对话段的立场。”XXX 和 YYY 两个人对这个问题的看法有什么不同”——多跳推理,向量检索完全搞不定。
4.5 混合检索
BM25 加向量检索加 Reranker,实测效果最好。BM25 捕获精确匹配,向量捕获语义相似,Reranker 做二次精排:
Reranker 推荐 bge-reranker-v2-m3 或 Cohere Rerank。
4.6 2026 标准 Pipeline
Orchestration 层:LangGraph 负责控制流,LlamaIndex 负责检索模块,这是 2026 年的生产默认组合。
4.7 Agentic RAG:什么时候需要
如果你的查询是确定性的(”上次老刘说的那本书叫什么”),标准 pipeline 完全够用。
如果你的查询是开放性的、需要多轮推理(”帮我梳理群里过去两年关于 AI 编程工具的讨论,看看观点是怎么演变的”),就需要 Agentic RAG——系统不是一次检索就生成,而是一个 Agent 在循环里工作:提问→检索→分析→补充提问→再检索→综合回答,直到有把握为止。
这已经超出了”搭个知识库”的范畴,进入了”搭个研究助手”的领域。生产环境的评估用 Ragas 加 Langfuse,入门可以看 LangGraph 的 Agentic RAG 教程。
五、聊天记录做知识库的优势
5.1 知识密度极高
你的朋友不会在对话里写废话开头”在当今快速发展的技术环境下…”。聊天是精力最集中的知识交换——问得直接,答得干脆。一个技术讨论群的聊天记录,信息密度秒杀同等字数的博客文章。
5.2 隐性知识丰富
正式写作中,人们会省略”显然”的东西。但聊天里,”为什么用 Redis 不用 Memcached?”——回答会包含那些”太基础了没人写进博客”的决策逻辑。这种知识买不到。
5.3 观点多元
一篇博客是一个人的观点。一个群聊是五个人从不同角度的碰撞。当你在知识库里检索一个技术选型,你能同时看到支持和反对的声音,而不是一个人的结论。
5.4 时序信息完整
聊天记录天然带时间戳。你可以看到某个人对某个话题的认知演变——2022 年他觉得 Kubernetes 过度设计,2024 年他在群里分享生产环境上 K8s 的踩坑记录。这种演变在正式输出中几乎不可见。
5.5 个性化适配
如果你的知识库主要来自你和朋友的对话,那么它的表述风格、术语习惯、知识层次天然适配你的认知模式。检索出来的内容你看得懂、读得进,不需要从通用知识库的抽象描述中二次翻译。
六、聊天记录做知识库的劣势
6.1 噪声问题严重
聊天中 70% 以上的内容是社交性、确认性、情绪性的,和知识无关。清洗这道工序决定了最终质量,而清洗不便宜——尤其是 LLM 辅助清洗的方案,成本可能比预想的高。
6.2 结构性差
博客有标题、段落、章节。聊天是扁平的消息流,没有结构。你需要额外花力气划分话题层级、提取关键论点、建立关系图谱。不做这一步,知识库就是一坨扁平文本,RAG 检索精度上不去。
6.3 上下文依赖
聊天充满省略和代词。不做上下文修复,单条检索结果经常是不可理解的。做上下文修复,又引入了信息损失和成本。这是一个真实的 trade-off。
6.4 时效性污染
朋友 2022 年说”Vue 3 还不成熟,不建议上生产”,到 2025 年这已经过时了。聊天记录不会自动过期,过时信息会持续污染检索结果。
在 Agentic RAG 时代有了更好的处理方式——让 Agent 在检索到旧内容时,自动触发一次时效性核验:检索到 2022 年的技术观点时,顺手搜索一下该技术当前的现状,在回答里标注”此观点来自 2022 年,当前情况请参考…”。这是 Agentic RAG 比静态 RAG 真实多出来的价值之一。
6.5 隐私与伦理问题
这是最敏感的一点。你对自己的聊天记录有使用权,但如果知识库里包含他人的发言,而对方不知情——这里有一条灰线。技术上合规不等于伦理上合理。个人使用和向第三方提供,差异巨大。群聊中存在”发言者认为是临时对话,没想到会被持久化检索”的合理期望。
务实建议:仅限个人使用,不公开、不分享原始数据,不对外提供基于他人发言的问答服务。
6.6 观点未经验证
博客至少经过了自我审查,论文经过了 peer review,而聊天是随口一说。”我觉得这个方案不行”——可能只是那天他心情不好。聊天记录中的观点可信度天然低于正式输出,知识库需要在 metadata 里标注信息来源类型,避免被当作权威引用。
七、一个最小可行方案(2026)
如果你想今天就开始,最精简的现代版本如下。和 2025 年版的 ChromaDB 方案相比,主要升级是换成了 Qdrant(性能更好,本地 Docker 部署简单),以及加上了 Contextual Retrieval 的上下文前缀步骤。
如果未来想升级到 LightRAG,Qdrant 可以保留,直接在上面加一层图存储,路不会走窄。
2025 年版结尾说”最难的部分不是技术实现,而是在噪声中保留信号、在碎片中还原语义的判断力”——这句话仍然成立。
一年多后技术层面的变化是:Embedding 模型便宜了,GraphRAG 有了实用的轻量版(LightRAG),Contextual Retrieval 解决了上下文丢失的老问题,Agentic RAG 让复杂查询变得可能。
但本质没变:聊天记录是矿石,价值在里面,挖出来要工夫。
动手做个最小版本。你朋友在某个深夜群里随口说的那句话,三个月后变成知识库里召回的第一条结果,比任何搜索引擎都精准。这件事值得做。
PS:微信永远是个让人恶心的东西。
我是AI最严厉的父亲:
连路过的母狗都会撩一下的AI工程师
技术架构 / 自动化体系
研究 AI、架构、人类行为模式
擅长把复杂拆开,把混乱整理成能落地的结构
股票 & 加密货币投机者
内容方向:AI、工具、自动化、投机逻辑
常驻技术世界,偶尔经过情绪地
V:cat9999sss




暂无评论内容