
一个人做内容,日更不断更。到目前为止发了十几篇长文,篇均12万曝光,涨粉累计 9000+,书签率稳定在0.5-1%——每一百个看到的人里就有一个觉得内容值得存下来以后用。
不是我文笔好。是背后跑着一套AI内容生产系统——从选题、找素材、写稿、配图到数据复盘,全流程AI执行,我只做判断。
公开分享的Claude Code工作流。他用这套思路年发13000条内容,同时运营7个平台,年涨粉70万。我拿过来之后根据自己做X长文的需求改了不少,这篇分享的是改完之后我在用的版本。
栋哥讲过一个很本质的问题:大部分人用AI做内容是碎片化的——有想法就问AI,拿到答案就发,发完就忘。下次有想法又从零开始。
他的解法是把整个过程变成闭环:想法记进选题库 → AI检索素材库找可复用的东西 → 套已验证的框架写 → 发布 → 数据复盘 → 把有效的规律沉淀回方法论。每次创作都在给系统加东西,不是每次重新发明轮子。
这个思路我直接拿过来了。下面是我改出来的版本。
![图片[1]-一个人日更长文,篇均12万曝光——我的AI内容系统长什么样-🎉数字奇遇🎉](https://pbs.twimg.com/media/HHsQxrvbAAAYCao?format=jpg&name=large)
四层知识库
我用Obsidian管内容,Claude Code执行。系统拆成四层。
AI写东西最大的问题不是写不好,是写出来不像你。长文读者一个字一个字读的,AI味一重就感觉不对。
所以我把自己说过的话全部存下来——推文、微信聊天记录里聊到的观点、录音、随手记的碎片想法。然后从里面提炼出一份写作风格指南:我说话喜欢先下结论再给理由,喜欢用数字不用形容词,喜欢拿别的行业的逻辑来解释当前这件事,不用鸡汤收束。
AI每次写稿之前先读这份指南,出来的初稿至少七八分像我自己说的。写完再跑一遍”去AI味”检测,把机器感太重的表达标出来让我改。
检测什么?列几条最常踩的:
-
营销体大词:赋能、闭环、打通、底层逻辑——看到就删
-
替读者说话:「你可能觉得……」「很多人会问……」——你怎么知道别人觉得什么
-
指令语气:「记住」「一定要」「核心就一句话」——我是在聊天不是在上课
-
虚构数据:「90%的人不知道」——你哪来的90%
-
独立短句装戏剧感:一句话。一个词。成段。——这个最AI味
-
加粗口号金句:真正厉害的人都在…… ——删
这些规则存在系统里,AI写完初稿自动跑一遍,命中了就标红。两步加上去之后,长文的人味改善很明显。
47个同类账号的拆解、1100多篇内容的数据、爆款文章的结构分析、可复用的概念和金句。
每次写新文章之前,AI先翻一遍素材库:同类话题谁写过、什么角度跑出了数据、什么结构读者愿意存。不是抄,是站在别人的数据上选路线。
拆完47个账号之后,有几个发现直接影响了我的选题策略:
-
100万+曝光的内容只有5类:刚需工具教程、医学健康科普、AI+搞钱、人设解析文、资源合集。其他类型几乎不可能过百万
-
书签率和曝光不一定正相关。有些文章曝光一般但书签率很高,说明内容有长期价值,读者存了以后用——这类内容值得反复写
-
涨粉和曝光也不一定正相关。人设文119K曝光涨了156粉,教程文77K曝光只涨25粉。人设让人想follow这个人,教程让人存了就走
选题池 → 待深化 → 创作中 → 已发布。池子里长期保持十几个随时能写的选题,十几个需要补素材的备选。不是临时想写什么就写什么——按策略从池子里挑。
选题分几个赛道轮着来:项目实战、AI搞钱赛道拆解、草根低门槛生意、AI新范式趋势。每个赛道的选题强度不一样——硬核工具教程曝光最高,人设自我介绍涨粉最猛,数据复盘受众窄但书签率好。根据当前目标选选题:要曝光就发教程,要涨粉就发人设,要沉淀就发复盘。
什么标题有效、什么选题能爆、什么结构书签率高——全从自己的发布数据里提炼。
标题是最容易量化的部分。跑了十几篇长文之后,出数据的标题基本落在四个模式里:
![图片[2]-一个人日更长文,篇均12万曝光——我的AI内容系统长什么样-🎉数字奇遇🎉](https://pbs.twimg.com/media/HHsRIuGa0AArljw?format=png&name=large)
发之前过一遍:有没有具体数字?有没有身份标签?有没有反差?读者看完标题知不知道能得到什么?命中越多数据越好。
![图片[3]-一个人日更长文,篇均12万曝光——我的AI内容系统长什么样-🎉数字奇遇🎉](https://pbs.twimg.com/media/HHsQ6sKbwAA5b-s?format=jpg&name=large)
X长文的配图很关键。信息流里用户的注意力顺序是HERO图 > 标题 > 正文。图不行,标题再好也没人点。
我的原则:HERO图、标题、钩子三件套信息不重复。HERO图一眼告诉你”这是什么类型的内容”,标题给一个让人停下来的数据锚点,正文第一段展开细节。三个东西传递三层不同的信息。
配图两种风格,根据内容类型自动选:
教程类用信息图——白底、浅色装饰气泡、圆角卡片、扁平图标、大号中文标题,像SaaS官网那种干净的hero banner。观点类用概念海报——大字作为画面骨架,角色和文字咬合,像展览海报不是PPT。
每篇长文一张封面加两三张内页信息图。AI根据文章内容生成prompt,调GPT Image 2的API出图,下载裁切到需要的比例。以前Canva一张调半小时,现在10分钟出三张。
![图片[4]-一个人日更长文,篇均12万曝光——我的AI内容系统长什么样-🎉数字奇遇🎉](https://pbs.twimg.com/media/HHsRExJawAAB_RG?format=png&name=large)
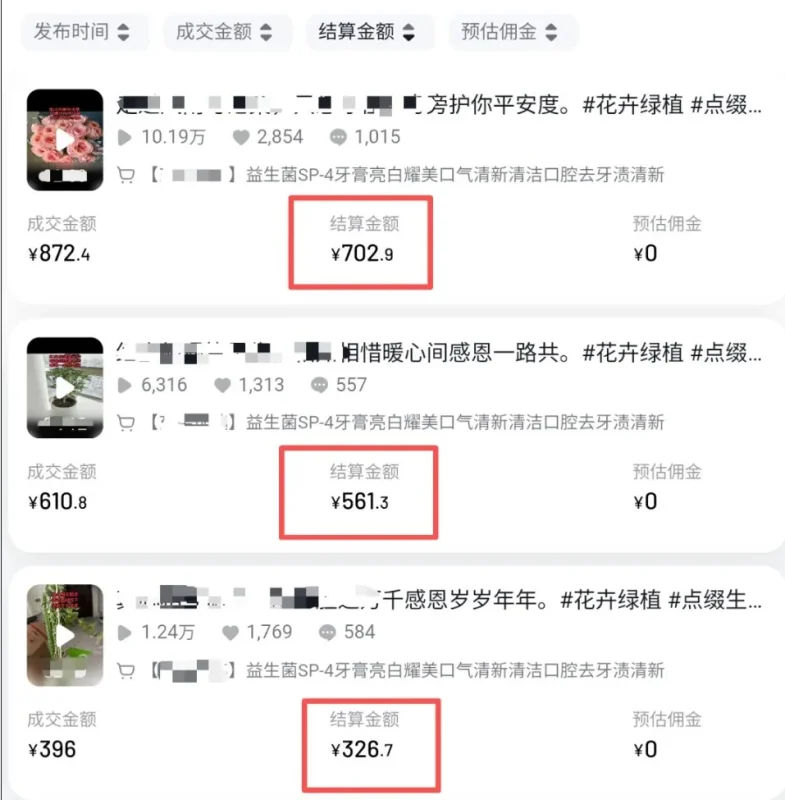
篇均12万左右,书签率0.5-1%。AI算命那篇书签率最高,1.01%——AI+搞钱+信息差的组合,读者存得最积极。
从数据里长出来的规律
“从数据里长规则”是dontbesilent的核心方法论。以下是我自己的X长文数据跑出来的具体规律:
标题里必须有具体数字。
“4个月变现10万””$155 vs $15″”452%收益率”——跑出来的长文都带硬数字。信息流里数字是最容易让人停下来的东西。
AI教程类长文稳定10万以上,纯投资内容很难过5万。来这个账号的人想看”AI怎么用”,不是看”怎么炒股”。
“帮你省时间”是底层传播逻辑。
公众号采集、Codex入门、配图实战——所有爆款长文的共性是”我帮你试过了、踩坑了、整理好了,你照着来”。
爆款公式:硬核教程或真实经历 + 具体数据锚定 + 可复现路径。
没有一篇爆款的标题是抽象概念。全是”我做了X,结果是Y”的结构——分享经历加数据,不教课。
这些规则每发一篇新文章就更新一版。系统在自我修正。
你可以直接用
dontbesilent的dbskill(GitHub 4000+ star)是个很好的起点。你也可以像我一样,拿他的核心思路过来根据自己的需求改。
不用一步到位。先把选题池和素材库建起来,跑两周,让数据告诉你该往哪个方向调。




暂无评论内容