
![图片[1]-Crawlee:使用 JavaScript 和 Python 构建可靠、快速的网络爬虫-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2025/07/226e54339320250711103158-800x296.webp)
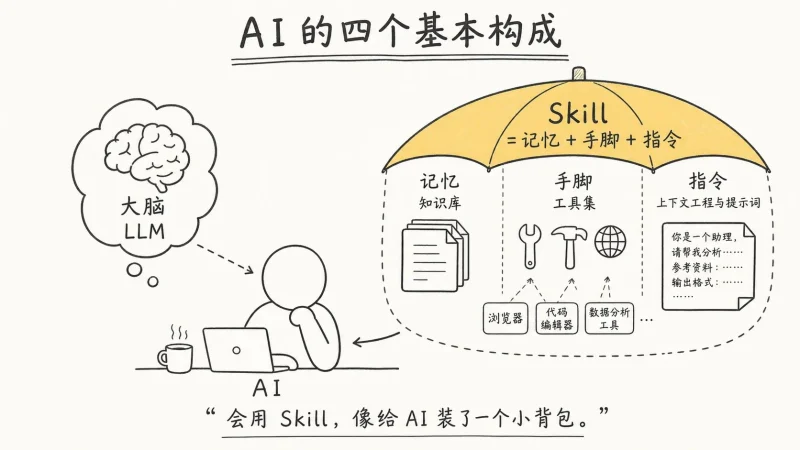
Crawlee 是一个用于 JavaScript 和 Python 的网络爬虫库,旨在简化和加速网络爬虫的构建过程。它能自动处理阻塞、抓取、代理和浏览器相关的问题,使开发者可以专注于爬取数据的核心逻辑。
使用 Crawlee,你可以轻松地创建自定义的网络爬虫,无需手动处理复杂的底层细节。该库提供了强大的功能,包括:
* **自动处理常见问题:** Crawlee 自动处理如请求阻塞、代理管理和浏览器控制等常见的爬虫难题。
* **易于使用的 API:** 库提供简洁的 API,使得开发者可以快速上手并构建自己的爬虫。
* **集成 Playwright 和其他工具:** Crawlee 能够与 Playwright 等无头浏览器集成,从而可以抓取动态渲染的网页。
* **数据存储和导出:** 爬取的数据可以轻松地保存为 JSON 格式,并导出为 CSV 等其他格式。
* **可扩展性:** Crawlee 具有高度的可扩展性,可以处理各种规模的网络爬取任务。
你可以通过命令行工具快速创建 Crawlee 项目,并使用提供的模板开始构建你的爬虫。以下是一个简单的示例,展示了如何使用 PlaywrightCrawler 抓取网页:
“`javascript
import { PlaywrightCrawler } from ‘crawlee’;
const crawler = new PlaywrightCrawler({
async requestHandler({ request, page, enqueueLinks, pushData, log }) {
const title = await page.title();
log.info(`Title of ${request.loadedUrl} is ‘${title}’`);
await pushData({ title, url: request.loadedUrl });
await enqueueLinks();
},
maxRequestsPerCrawl: 20,
});
await crawler.run([‘https://crawlee.dev’]);
await crawler.exportData(‘./result.csv’);
“`
这段代码创建了一个 PlaywrightCrawler 实例,它会抓取 `https://crawlee.dev` 网站上的页面,提取标题和 URL,并将结果保存到 CSV 文件中。
总而言之,Crawlee 旨在使网络爬虫的构建和维护更加高效和可靠,让开发者能够专注于数据抓取的核心业务逻辑,而不是花费大量时间处理底层技术细节。它是一个永久免费且开源的项目,由 Apify 构建。
apify/crawlee: Crawlee—A web scraping and browser automation library for Node.js to build reliable crawlers. In JavaScript and TypeScript. Extract data for AI, LLMs, RAG, or GPTs. Download HTML, PDF, JPG, PNG, and other files from websites. Works with Puppeteer, Playwright, Cheerio, JSDOM, and raw HTTP. Both headful and headless mode. With proxy rotation.
https://github.com/apify/crawlee
Crawlee · Build reliable crawlers. Fast.
https://crawlee.dev/





暂无评论内容