
![图片[1]-Happy-LLM:从零开始的大语言模型原理与实践教程(Datawhale开源项目)-🎉数字奇遇🎉](https://www.freeyong.com/wp-content/uploads/2025/07/b39c37fb8b20250707085443-800x603.webp)
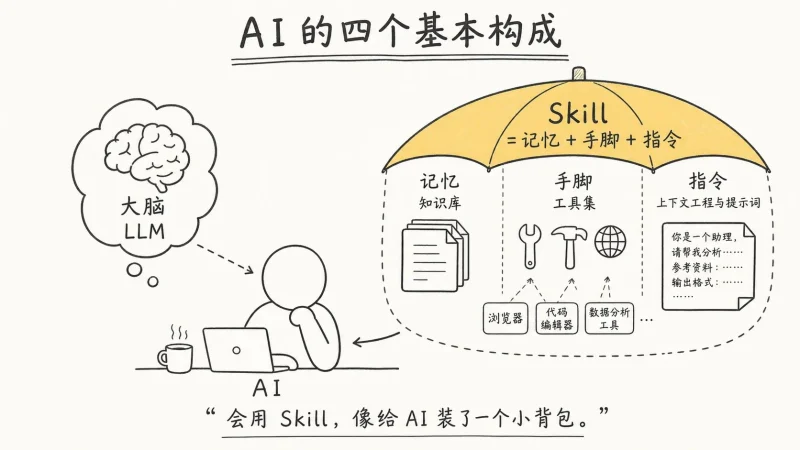
Datawhale 推出的《Happy-LLM》是一个旨在帮助学习者深入理解大语言模型(LLM)原理和训练过程的开源教程项目。该教程从 NLP 的基础概念出发,逐步深入到 LLM 的架构基础和训练过程,并结合主流代码框架,演示如何搭建和训练一个 LLM。学习者将能够掌握 Transformer 架构、预训练语言模型原理,了解现有大模型结构,并亲手实现 LLaMA2 模型,掌握从预训练到微调的完整流程,以及 RAG、Agent 等前沿技术。
**教程内容结构:**
* **基础知识部分(第1-4章):** 涵盖 NLP 基础概念、Transformer 架构(包括注意力机制和 Encoder-Decoder 结构)、预训练语言模型(Encoder-only、Encoder-Decoder、Decoder-Only 模型对比)以及 LLM 的定义、训练策略和涌现能力分析。
* **实战应用部分(第5-7章):** 引导读者动手搭建 LLaMA2 模型,训练 Tokenizer,预训练小型 LLM;介绍使用 Transformers 框架进行高效微调(包括 LoRA/QLoRA);以及 LLM 的应用,如模型评测、RAG 检索增强和 Agent 智能体。
**学习对象:**
该项目适合大学生、研究人员和 LLM 爱好者,建议具备一定的编程经验(特别是 Python)和深度学习、NLP 领域的相关知识。
**学习方法:**
建议将理论和实践相结合,复现代码,参与 LLM 相关的项目与比赛。同时,鼓励关注 Datawhale 及其他 LLM 开源社区,积极提问和交流。
**项目特点:**
* **开源免费:** 提供完全免费的学习内容。
* **系统性:** 从基础到实践,全面覆盖 LLM 的原理和应用。
* **实战性:** 强调动手实践,帮助读者真正掌握 LLM 的开发技能。
**贡献方式:**
欢迎通过提交 Issue 报告 Bug、提出功能建议、完善内容或优化代码等方式参与项目贡献。
**模型下载与体验:**
教程中涉及的模型可以在 ModelScope 下载,并体验创空间。此外,还提供带有 Datawhale 开源标志水印的 PDF 版本下载。
datawhalechina/happy-llm: 📚 从零开始的大语言模型原理与实践教程
https://github.com/datawhalechina/happy-llm





暂无评论内容